--Reference sources:
------
- Bernhard Karlgren: Analytic Dictionary of Chinese, Dover Publications 1974 (from the 1923 original)
- Edoardo Fazzioli: Understanding Chinese Characters, Collins 1987
- Rich Harbaugh: Chinese Characters, A Genealogy and Dictionary, Zongwen.com 1998
- the Pocket Oxford Chinese Dictionary, Oxford University Press 2003
- Wu Jianshin: The Way of Chinese Characters, Cheng & Tsui 2007
- 商务国际现代汉语词典, 商务印书馆 国际有限公司, 2014
- the mdbg.net site
.
--Disclaimers:
------
the author thought better not to delay advertising this original approach for the sake of personal perfection but acknowledges...
- inaccuracies, as he was bound to make mistakes
- incompleteness in this systematic study
- except for rare exceptions, all characters are taken from the Pocket Oxford
- some presentation features have not yet been applied to all existing pages
- substandard presentation outside of the use of Firefox on an ordinary computer
- no implementation of the database necessary for personalizing character and marker pages by teachers and students
Table of content
.
--Introduction:
------
- The traditional approach (see Jianhsin Wu) distinguishes six categories of characters:
- "pictographs (象形)
- explicit characters (指事)
- associative compounds (会意)
- picto-phonetic characters (形声)
- mutually explanatory characters (转注)
- phonetic loan characters(假借)"
- While accurate and useful, it
- fails to mention the recursive or hierarchical manner in which characters are created
- takes too much emphasis away from phonetic derivation
.
- Based on empirical results by this mere amateur, the present approach proposes to cure these imbalances by instead stating:
- Chinese characters are built like an onion in multiple layers, each characterized by a special process
- the first layer, by the overall visual shape created by its elementary strokes
- the second layer, by the overall sense made from the semantic meaning of its individual components
- outward from this second layer, potentially itself including, by the overall sound denoted by a particular component
- To analyze a given Chinese character is therefore like peeling an onion, each peel but the last made out of components. Components, hitherto called markers, are the true linguistic units of written Chinese characterized by:
- a visual shape, made out of strokes into a unique pattern admitting slight deformations
- a sense, extendable through semantic derivations
- a phonetic sound, extendable through phonetic spreading
- Starting therefore from the outer layers, if any, till nothing remains but the first, one can analyze Chinese characters recursively and classify them into three categories:
- phonetic derivations of a marker picked for its phonetic sound, a category itself divided into three subcategories of characters:
- the meaning derives exclusively from one or several other markers in a semantic role
- the meaning derives from both the phonetic marker and other semantic markers
- the phonetic marker remains alone but is reused to represent the meaning of an otherwise unrelated homonym
- pure semantic associations, made out of two or more markers solely taken for their semantic meaning and markers themselves
- primitive markers, which admit no further decomposition
- Because the first category represent more than 90% of all Chinese characters, and because phonetics naturally lends itself to recursive decomposition, e.g. 踮, 店, 占, the present approach gives priority to capturing and displaying phonetic markers and the phonetic information they convey. Because the combination of semantics and phonetics is optimal for memorization, e.g. 鞋, a shoe (xié) is "leather" to go on "the ground" (guī/jiē...), the present approach further emphasizes the second subcategory of this first category, whenever present.
.
- Naturally the present approach remains entirely consistent with the traditional one:
- The first subcategory of the first category corresponds to the traditional picto-phonetic characters, one semantic marker a radical used as a classifier, e.g. 站 and 战. However one should note that:
- some radicals may play the role of a phonetic marker, e.g. 工 in 空
- derived information is not narrowly determined, e.g. the semantics of 艹 (节 to 药) and the phonetics of 占 (站 to 店)
- this subcategory includes a few aberrations stemming from graphical confusions, e.g. 封 and 陈 (see Karlgren)
- The second subcategory corresponds to characters classified as both picto-phonetic and associative
- The third subcategory corresponds to phonetic loan characters, e.g. 我 (see Jianhsin Wu)
- The second category corresponds to associative compounds, e.g. 明, 品, now seen in the larger context of markers, e.g. 明 and 萌
- The last category corresponds to both pictographs and explicit characters, the difference in the way each type uses strokes to convey meaning being played down
- The traditional family of mutually explanatory characters is merged with picto-phonetic characters as the examples normally given to illustrate it, such as 考 and 蛇, do not seem to warrant extra recognition.
.
Table of content
.
--Phonetic tables:
- it is well known how to break chinese sounds in initial and final components and how to lay out initial consonants on a two-dimensional table
- However there are many existing variations of the latter layout and the present methodology claims optimality:
- each phonetic marker can be seen as a liquid drop which,
upon falling on our 6x6 phonetic tables, is allowed to spread along columns (faster) and rows (slower),
and in the case of final sounds, along the implied dimension representing the (-, -n, -ng) consonantic ending
- this enables one to represent each phonetic marker simply on a phonetic map (e.g. 店, 佥, 占 and 合)
- the "er" sound is a special case which is represented on phonetic maps as equivalent to the initial consonant r with no ending
- the initial table is organized so as to acquire predictive value when confronted with two initial sounds sharing neither row nor column
e.g. marker 今 represents initials h (han) and j (jin) - find the continuity through initials g (gan) and n (nian)
- this predictive power is enhanced when blank spaces in the initial table are taken into account.
for a blank space can be "invaded" by adjacent initials, e.g.
- sh, the retroflex sibilant, can play the role of the missing dental sibilant, a well known fact (e.g. 也)
- h, a velar, can play a double role either as a sibilant or a liquid/nasal, a little advertised fact (see 行 and 各)
- The latter observation enables one to consistently account for the cases of
- "no initial consonant" as indeterminate in one dimension until the marker phonetic spread has been established (e.g. 客)
- w and y, "no initial consonant" symbols which may also denote a link to labials for w (e.g. 门), and palatals for y (e.g. 佥)
Table of content
.
--Sound lists and phonetic maps:
- All characters analyzed have been reduced to the marker responsible for its phonetics, e.g. 放 appears as 方
including when the character itself played this role, i.e. 方 also appears as 方.
- sound lists
To each sound then corresponds the list of all related markers (e.g. the fang list is simply made of 方)
- phonetic maps
Conversely, for each marker, all characters of which it is a direct component are listed against our phonetic tables,
highlighting the role of the marker in each derivative. This determines the phonetic map of the sounds it can denote (e.g. 佥).
- Recursive phonetic decomposition
The reduction process has been pursued in a recursive manner so as to link markers according to phonetic descent
- e.g. the marker 星 convey the sound xing in inheritance from the marker 生
- by convention and without losing any information, the phonetic map of each marker has been limited to its immediate sons
i.e. 匕 engenders 比 over the sound bi, and 比 in turn spreads to the sound pi.
but, as it happens within our current character set, sound pi does not figure in the phonetic map of 匕 nor 匕 on the pi sound list.
- Untreated characters
Whenever a character could not be reduced in this way, it has been added at the end of its sound list after the "..." symbol
- it could be because the author was not able to formulate any reliable hypothesis
- but most cases simply account for pure semantic associations (e.g. 好) or primitive shapes (e.g. 习).
- The latter cases should be considered as "proto-markers" which happen not to have yet been reused in derivations.
- As a special case, e.g. 肉, this is because the character is almost always reused under a different, simplified form (月)
- The simplification process has "stranded" more such characters by
- either reserving simplification to reuse in combination (e.g. mdbg.net does not give
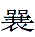 as the simplified form of 昜) as the simplified form of 昜)
- or creating highly stylized forms no longer matching any other marker, whether traditional or simplified (e.g. 习).
- simplification process
Sound lists and phonetic maps make is easy to trace its rational and its effect
- in some cases the visual shape of a marker has been simplified in a consistent manner (e.g. 𢀖 for 巠),
in line with the historical progression of pictographic characters towards increased abstraction. e.g. the evolution of 女
- or a visually complex phonetic marker has been replaced by a visually simple one with the same phonetics (e.g. 补 for 補)
- in yet other cases a new phonetic marker seems to have been introduced arbitrarily but in a rather phonetically consistent manner, e.g.
- as seen in 疟 from 瘧,
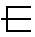 got its phonetics (nüe) from the marker 虐, got its phonetics (nüe) from the marker 虐,
whose phonetics itself derived from 虍, to fit in the (hu/nüe/lu/lü/xu) map of the latter.
Now used in both 疟 and 虐, has become a true phonetic marker, and both components of 虐 contribute its nüè sound .
- as seen in 双 from 雙 and 树 from 樹 with the potential additions of 欢 from 歡, 观 from 觀,
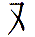 has been given a (guan/huan/shuang/shu) map in which one should probably insert the sound han of 汉 from 漢. has been given a (guan/huan/shuang/shu) map in which one should probably insert the sound han of 汉 from 漢.
- 广 is an interesting case. Like above, 广 has inherited its phonetics from marker 黃 now dropped from former form 廣.
Then, the 广 map has been extended in a (guang/zhuang/chuang) spread to absorb part of the 爿 map, 庄 from 莊 and 床 from 牀.
- finally, phonetic marking neither preserved nor transferred, simplification has created new "proto-markers",
either as primitives, e.g. 习 from 習, or as pseudo semantic associations, e.g. 边 from 邊.
- new characters
Structural analysis based on markers makes it easy to judge the quality of new character formation.
- For instance the character 烃 for hydrocarbon has been consistently created by conflating carbon 碳 and hydrogen 氢 both by
- shapes 火 of carbon and 𢀖 of hydrogen
- phonetics t of tan (carbon) and ing of qing (hydrogen)
- while respecting phonetics by extending the 𢀖 palatal spread (jing, qing) to dental neighbor ting
- note on marker representation
Although most markers are bona fide characters and exist in stand alone mode, some are not, including special shapes taken by radicals.
Extended Unicode code points cover the latter, e.g. 讠, ⺷. They also include some obsolete characters which survive in combination, e.g. 𢀖.
Whenever a marker is neither listed as a bona fide character nor yet found as a Unicode extension, a picture has been created to represent it,
e.g. 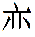 for the marker representing the phonetics of 变 and 蛮. for the marker representing the phonetics of 变 and 蛮.
Table of content
.
--Quantitative results:
- General results
| sounds accounted for (including ng and hng) | 403 |
| phonetic instances recorded | 2576 |
| characters left untreated | 285 |
| maker instances found | 2290 |
| phonetic markers identified | 1098 |
.
- Distribution of phonetic instances to sounds (approximative)
- Average number of phonetic instances per sound : 6.4
.
- presentation by quartile
| instances/sound |
1-5 | 6-10 | 11-15 | 16-41 |
| number of sounds (%) |
223 (55%) | 121 (30%) | 35 (9%) | 24 (6%) |
| number of instances (%) |
663 (26%) | 939 (36%) | 439 (17%) | 545 (21%) |
.
- detailed distribution
| number of instances/sound |
1 | 2 | 3 | 4 | 5 |
6 | 7 | 8 | 9 | 10 |
11 | 12 | 13 | 14 | 15 |
16 | 17 | 18 | 19 | 20 |
23 | 25 | 26 | 36 | 41 |
| number of occurrences |
47 | 37 | 54 | 45 | 40 |
32 | 24 | 26 | 19 | 20 |
12 | 5 | 9 | 4 | 5 |
2 | 5 | 2 | 1 | 2 |
3 | 5 | 1 | 2 | 1 |
.
- Distribution of phonetic instances to markers (approximative)
- Average number of phonetic instances per marker : 2.4
.
- presentation by quartile
| instances/marker |
1-3 | 3-6 | 7-9 | 10-13 |
| number of markers (%) |
945 (86%) | 135 (12%) | 19 (1.6%) | 4 (0.4%) |
| number of instances (%) |
1508 (66%) | 608 (26%) | 142 (6.0%) | 47 (2.0%) |
.
- detailed distribution
| number of instances/marker |
1 | 2 | 3 |
4 | 5 | 6 |
7 | 8 | 9 |
10 | 12 | 13 |
| number of occurrences |
514 | 299 | 132 |
79 | 42 | 14 |
12 | 4 | 3 |
1 | 2 | 1 |
Table of content
.
--Measuring phonetic spread (Ph):
- When a marker is used to represent more than one sound, the above quantitative analysis simply counts how many sounds it spans. For theoretical and practical reasons, a more refined measurement is called for. What follows is a proposal based on our 6x6 phonetic tables.
- Given a marker and all the sounds it represents, its phonetic spread is defined as the sum of three components:
- initial consonantic spread IC
- vowel spread V
- final consonantic spread FC
- initial consonantic spread:
If the marker represents a single consonant, its initial consonantic spread is zero.
If not, remembering the no-initial case is like any other and "er" is but a r initial),
first cover the marker spread with a minimal set of connected columns and rows, giving preference to:
- columns over rows,
- intersections occupied by a marker occurrence over empty connections,
- connections made without using a stretched consonant to connect the two rows or the two columns which it straddles.
then:
- For each column spanned, add 1, 1.5, 1.75, 1.875, 1.9375 according to the number of consonants involved, respectively 2, 3, 4, 5, 6
- For each row spanned, add 2, 3, 3.5, 3.75, 3.875 according to the number of consonants involved, respectively 2, 3, 4, 5, 6
- For each row-column connection, add 8 if this intersection is not occupied by a marker occurrence (i.e. the map is not truly connected)
- When a consonant such as sh or h is stretched to make a connection between the two rows or columns it straddles, assign it to both of the cells it occupies but do not count this duplication when computing the stretched row or column, except to ensure a minimum of 1.
- When a consonant such as sh or h is stretched to make a connection between the two rows or columns it straddles, assign it to both of the cells it occupies but do not count this duplication when computing the stretched row or column, except to ensure a minimum of 1.
- When a consonant is stretched but is not used to connect the two rows or columns it straddles, assign it to the cell which minimizes IC.
- vowel spread:
Compute the vowel spread in the same way as for the consonantic spread but for the three following differences:
- Include the main descending diagonal (from a to ü)into the covering set
- Use the scale 1, 1.5, 1.75, 1.875, 1.9375 in all three directions, row, column and diagonal
- Instead of 8, set the penalty for lack of connection to
- 2 in the presence of a common n or ng ending (e.g. iong and uang),
- 4 otherwise (e.g. uo and a)
- final consonantic spread:
Add 1 or 1.5 for any spread along the only one direction present
- examples:
Assuming the map for the following markers is complete:
| marker | Ph | notes |
| 星 | 0.000 | - no spread (IC=V=FC=0) |
| 店 | 0.000 | - no spread (IC=V=FC=0) |
| 㐫 | 0.000 | - no spread (IC=V=FC=0) |
| 司 | 1.000 | - fricative column initial spread (IC=1, V=FC=0) |
| 佥 | 1.875 | - palatal column initial spread, (IC=1.875, V=FC=0) - yan = yian |
| 门 | 2.000 | - labial column initial spread (IC=1, V=1 (diagonal), FC=0) - non phonetic occurrences do not count |
| 𢀖 | 4.000 | - palatal column + aspirated row with occupied connection, (IC=3 (1+2), V=0, FC=1) |
| 生 | 4.500 | - sibilant row + palatal column with occupied connection, (IC=3.5 (2+1.5), V=1 (diagonal), FC=0) |
| 兑 | 5.000 | - IC=3.5 (1+1.50+1) (retroflex (with sh) & dental (with y) columns + stretched sibilant cell), V=1.5 ("u" row), FC=0 |
| 月 | 6.000 | - IC=0 (y cell), V=5 ("i" row - yao = yiao - + unconnected ue), FC=1 |
| 行 | 7.000 | - IC=3.5 (2+1.5) (sibilant row + palatal (with y) columns), V=2.5 (1.5+1) (diagonal + "i" row - yan = yian), FC=1 |
| 工 | 8.000 | - IC=5 (1.5+1.5+2) (velar & palatal columns + unaspirated row), V=3 (1.5+1.5) ("i" row + diagonal), FC=0 |
| 各 | 8.000 | - IC=3.5 (1.5+2) (velar column + liquid row), V=4.5 ("e" and "o" columns + "u" row + diagonal), FC=0 |
| 圭 | 8.250 | - IC=4.75 (1+1.75+2) (velar & palatal columns + unaspirated row), V=3.5 ("i" column, "i" and "u" rows - wa = ua & ya = ia), FC=0 |
| 艮 | 8.250 | - IC=5.25 (1.5+1.75+2) (velar & palatal columns + unaspirated row), V=2 ("i" row + diagonal - yan = yian), FC=1 |
| 占 | 9.000 | - IC=4.5 (3+1.5) (unaspirated row + dental column), V=3.5 (1.5+1+1) ("a" column + "i" row + diagonal), FC=1 |
| 也 | 9.250 | - IC=3.75 (1.75+2) (dental (with sh and y) column + aspirated row), V=5.5 (diagonal + unconnected "uo"), FC=0 |
| 合 | 11.500 | - IC=7 (1.5+1.5+1+3) (velar, dental (with sh) and palatal columns + unaspirated row), V=3.5 (diagonal + "i" column and "i" row), FC=1 |
- comments:
- The phonetic tables themselves structure the apparent randomness of the phonetic spread. According to this structure, spreading has a cost measured by the proposed Ph, designed to reflect the preferential manner in which spreading occurs.
- Ph is meant to better reflect the real underlying phenomenon than just counting the number of sounds covered by a marker.
- At the two extremes, the two approaches coincide. To a zero Ph corresponds a single sound (e.g. 星), while a high Ph is generally correlated with a high number of sounds (e.g. 合, mapping 10 sounds).
- But notice how a highly consistent marker can map relatively many sounds and yet come out with a low Ph. With 7 sounds, 兑 has a Ph of 5.0, and with 5 sounds, 佥 a Ph of 1.875.
- Conversely, with just two sounds with unconnected initial consonants, a marker will have at least a Ph of 8, casting doubts on the accuracy of the phonetic analysis. This penalty can be cured by looking for attested but little used connections. For instance 佫 (he4), a syllable recorded by mdbg, acts as a connection for marker 各. This criteria can help resolving some untreated characters, e.g.
- marker 兄 is listed for sound "xiong" while character 況 is left untreated, as assigning sound "kuang" to 兄 would raise its Ph to a suspicious 10 (IC=8 - unconnected k and x, V=2 - unconnected ua and io in the presence of a common ng, FC=0). The solution may be to add mdbg listed 怳 (huang3) to the 兄 map, which would lower its Ph to a more acceptable 5 (IC=3, V=2, FC=0) by providing the initial consonant connection.
Table of content
.
--Transliteration and translation of foreign characters:
- In the past Chinese has borrowed a number of words from foreign languages. This continues today especially from American English.
In particular a systematic understanding of these mechanisms is a prerequisite for learning scientific or technical vocabularies.
- Transliteration attempts to reproduce the original sound, normally one Chinese character per syllable.
Sound lists and phonetic maps convey how it works and provide English speakers with words they already know
e.g. 咖啡 (kāfēi) stands for coffee, 沙发 (shāfā) for "sofa" and 鲨鱼 (shāyú) for shark
- In most cases, transliteration tries to combine the phonetic marker with a semantic one as an extra clue:
e.g. the "metal" radical appears in both 铀 (yóu) for uranium and 钚 (bù) for plutonium (the Pinyin "b" sounds almost like an English "p")
- Translation carries the original meaning and may resort to periphrases. While discarding phonetic information, it may convey visual clues:
e.g. 十字架 stands for "a cross", i.e. "a wooden frame in the shape of the number 10"
- Note that even when neither visual nor phonetic clues are present, translations can convey cultural history,
e.g. planets visible by the naked eye are named after traditional elements such as fire (Mars, 火星) or wood (Jupiter, 木星)
but planets only visible with a telescope are given names freely translated from Western astronomy
such as King of Heaven (Uranus, 天王星) or King of the Sea (Neptune, 海王星) or King of Hell (Pluto, 冥王星)
- With transliteration, the characters picked for their sounds retain their original meaning for those who take the time to think about it.
This can be the source of subtle connotations:
e.g. the second character in 耶稣 (Yēsū) for Jesus combines two markers, 鱼 for fish and 禾 for cereal,
an allusion to a miracle attributed to Jesus in the Gospels.
On the other hand one can speculate whether John Harvard would have assented to the translation of his name as 哈佛 (Hāfó):
a good approximation of the syllable "vard" (the "v" initial is close to an "f", as seen in the German vater for father), 佛 (fó) means Buddha.
Table of content
.
--Visual list:
- Some markers play no phonetic role and so cannot be selected through the sound lists, only by their shapes through the visual list.
- This is typical of the radicals used for classification, under an abbreviated form in general, such as 氵for water or 艹 for grass.
- But not all purely semantic markers are radicals, e.g. marker
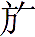
- However a visual classification is not only made to index all markers, but as a learning tool.
For one should first segment large sets into easily differentiated families, and then study the more subtle differences between family members.
Similarly, even when suboptimal, most attempts at sound classification have been an indispensible means to build classroom pronunciation drills.
- For more details specific to our visual methodology.
Table of content
|